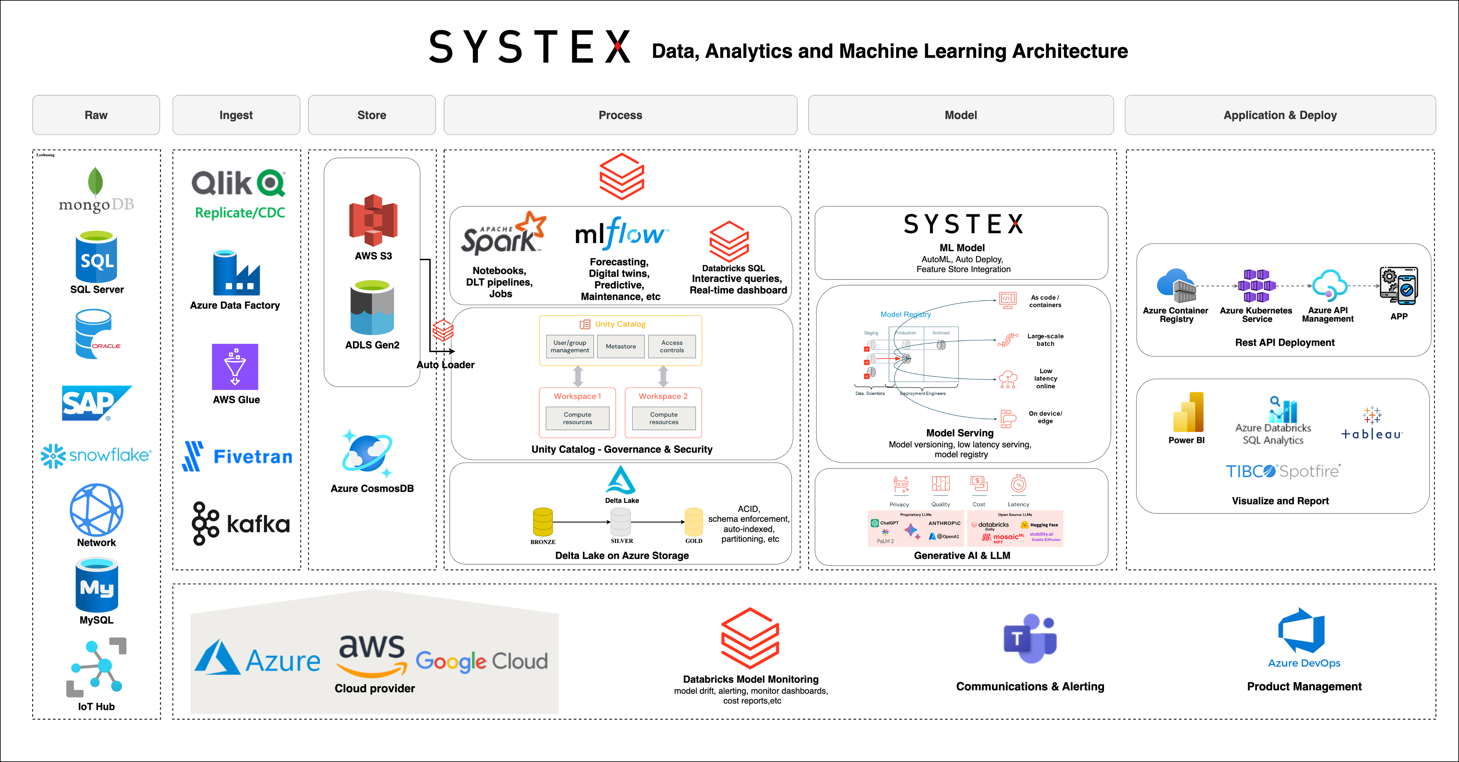
構建雲原生現代化湖倉一體架構 Databricks Intelligence Platform,實現數據管理與分析的極致效能
建構現代化智慧平台,支持數據分析及 AI/ML 作業提升
ChatGPT 問世、AI 教父所帶來的全新 AI 時代,不單是憑靠演算法及強大 GPU 算力,各大產業也思考如何靈活運用企業內數據,推出更具商業價值的 AI 應用。
Databricks Intelligence Platform 以現代化 Data + AI 架構為核心,結合高效能的分散式運算與雲端物件儲存,協助企業快速整合、彙整並管理各類型數據,無論是結構化、非結構化或即時流式資料。平台內建強大的 AI 與機器學習工具,支援從資料收集、清理、分析到模型訓練與部署的全流程,並透過自動化與協作式的方式,讓資料科學家與業務團隊能夠無縫合作,加速 AI 應用落地。
Databricks Intelligence Platform 不僅提升數據治理與安全性,更能靈活擴展至多雲環境,協助企業發揮數據最大價值,實現數據驅動的創新與 AI 民主化。
優勢及功能
一、湖倉一體架構設計,六項構面特性
湖倉一體以 ANCHOR 作為定義標準,中文翻譯為錨點,成為湖倉一體浪潮下的核心特性。
A:『All Data Types』支持多類型數據 (Structured & Unstructured),關聯式資料表、文件、圖像、影音,結構化數據和非結構化數據存儲。
N:『Native on Cloud』雲原生架構設計,自由增減運算和儲存資源,彈性的架構設計。
C:『Consistency』數據一致性,透過支持完善的 ACID 事務機制,保障不同用戶同時查詢和更新同一份數據時的一致性。
H:『High Concurrency』超高併發,支持數十萬用戶使用複雜分析查詢併發訪問同一份數據。
O:『One Copy of Data』一份數據,所有用戶,包含:BI 分析師、數據科學家…等可以共享同一份數據,避免數據孤島。
R:『Real-Time』即時 T+0,通過全量數據 T+0 的數據流處理和依照需求即時查詢,滿足基於數據的事前預測、事中判斷和事後分析。
二、基於雲原生相同的開放性儲算分離設計
以低成本物件儲存庫 Object Storage,Databricks Intelligence Platform 採用低成本物件儲存庫(如 ADLS Gen2、AWS S3),並透過 Delta Lake 提供高效能的數據管理功能。該平台支持分散式運算引擎,例如 Spark,用於資料轉換(ETL/ELT)、即時流處理,以及 AI/ML 作業。
三、自然語言分析與 AI/BI 數據分析
透過結合複合 AI 系統與語意理解引擎,讓組織中每一位成員都能以自然語言或低程式碼方式,輕鬆探索、查詢並視覺化資料,無需依賴資料專業人員即可獲得即時且深入的商業洞察,同時平台內建的 AI/BI 儀表板與對話式 Genie 介面,能根據用戶反饋持續學習並優化分析結果,並與 Unity Catalog 緊密整合,確保數據治理、譜系追蹤與安全性,讓資料分析流程更簡化、資料新鮮度更高,且可無縫分享給組織內所有人,實現真正高效、低門檻且具產業領先性的自助式數據分析與決策支持。
四、提供數據目錄,強化數據共享與敏捷的 AI/ML 科學作業
透過統一的數據目錄(Unity Catalog)整合企業內部所有結構化與非結構化資料資產,實現跨部門、跨團隊的數據共享與協作,並結合細緻的權限控管、元數據管理與數據譜系追蹤,確保數據安全與合規,同時大幅提升資料搜尋、探索與重用的效率,讓資料科學家、分析師及 AI/ML 團隊能夠在單一平台上快速發現、存取並運用高品質數據,靈活建立與部署機器學習模型,推動敏捷的 AI 創新與科學實驗流程,最終加速企業數據價值的釋放與智能應用的落地。
五、Mosaic AI Gateway 和大型語言模型(LLM)支持:
透過 Mosaic AI Gateway 提供企業級的生成式 AI 能力,讓用戶能夠安全且高效地存取、調用及管理各類大型語言模型(LLM),不僅支援自有模型的訓練與微調,也能無縫整合第三方 LLM 服務,並結合細緻的權限控管、審計追蹤與資料治理,確保敏感資訊與知識產權的安全,同時讓資料科學家、工程師與業務團隊能在單一平台上靈活開發、測試與部署各式生成式 AI 應用,從自然語言查詢、智能問答到自動化內容生成,全面加速企業 AI 創新與智能化轉型。
主要優勢
Databricks Intelligence Platform 以統一的 Lakehouse 架構融合資料湖與資料倉儲的彈性與高效分析能力,支援多格式、多來源數據的整合與 ACID 事務處理,讓企業能夠在單一平台上高效管理與運用所有數據資產。
平台內建 Mosaic AI Gateway 與大型語言模型(LLM)支援,不僅讓企業能安全靈活地調用、訓練與整合各式生成式 AI 模型,還結合權限控管與資料治理,協助企業快速開發、部署多元 AI 應用,加速智能創新。
透過統一的數據目錄(Unity Catalog),Databricks 強化了跨部門、跨團隊的數據共享與協作,結合細緻的權限管理、元數據追蹤與數據譜系,讓資料科學家及 AI 團隊能敏捷探索、重用高品質數據,推動 AI/ML 科學作業與創新實驗。
此外,平台內建自助式分析與 AI/BI 工具,讓組織成員能以自然語言或 SQL 進行即時資料探索與視覺化分析,簡化資料洞察流程並加速數據驅動決策,全面提升企業營運效率與競爭力。